前言
可解释性是指人类能够理解决策原因的程度。模型一方面需要有一定的预测能力,另外还应当让人类可以理解,为什么模型会根据这些数据作出最后的判断,也就是中间的决策过程能够被解释。
模型的可解释性一直以来是一个热点且重要的研究方向。
线性回归非常好解释,一旦写出公式,人类很容易理解,但是只能表示线性关系,预测能力不足。另一边的极端是深度神经网络,它们可以在数据和预测之间建立非常深的非线性抽象联系,预测能力很好,但是中间过程几乎是黑箱,人类无法理解模型决策的依据。
所以大部分深度学习模型只能用评价指标来评价模型预测能力的好坏,而很少讨论其可解释性。
为什么要做可解释性分析
如果没有可解释性,在很多领域的实用性会受到限制
在很多实际领域,如军工、医学、法律、无人驾驶,即使模型预测能力再好,没有可解释性依然不会使用,如果用户不信任模型或预测,他们就不会使用它,所以模型的中间过程不能是黑箱,中间的过程必须用合理的理由解释清楚。。
欧盟的《通用数据保护条例》(GDPR)法律要求对算法的决策过程进行解释,以使其在用于患者护理之前透明
绝大部分的模型建立者的说法都是: “我的模型有很好的预测能力”
但是模型使用者的问题往往是: “我为什么要相信你的模型?”
揭露错误过程
有可能在数据集上的表现很好,但本身模型的预测有问题,如果没有可解释性可能难以看出,比如北极熊和棕熊的分类,可能模型实际上只是识别了背景是否有冰雪,可能模型本身的预测和实际需要的并没有什么联系。如果有可解释性,就可以删掉一些没有意义的特征从而改进模型。
3揭示新的成像表示物
可解释性方法还可以揭示新的成像生物标志物,从而了解深度神经网络的具体情况。
对可解释性的理解
可解释性指的是任何试图回答“模型为什么做出这种预测”问题的技术。我们想要弄清楚以下几个问题:
what?是什么驱动了模型的判断,公平性 why?为什么模型会给出这个预测结果,可靠性 how?我们如何信任模型的预测,透明度
可解释性方法的分类
可解释性方法可以分为Pre-Model、In-Model和Post-Model。
其中Pre-Model指的是解释独立于模型本身,只能应用于数据,比如PCA、t-SNE、聚类等。
In-Model指的是模型本身本质上可解释(一般是一些统计学、机器学习模型),有数理的推导过程,比如模型本身有因果性、外在约束以及自带特征权重等。比如线性回归、逻辑回归、决策树、SVM等。
Post-Model又称为Post hoc,指的是模型本身是黑盒,但是训练后应用可解释性方法(特征重要性、部分依赖性图)等,从而使得模型可以被解释。
通用的可解释性方法
特征重要性
给出不同特征的重要性权重
特征重要性可以告诉你哪些特征是最重要的或者是不重要的。
部分依赖图
PDP或者PD图
可以展示一个特征如何影响预测,显示特征对预测结果的边际效应。 partial dependence图可以告诉你一个特征是如何影响预测的。
SHAP
可以讨论各个特征对预测结果的贡献。 SHAP将预测值解释为每个输入特征的归因值之和,相比于特征重要性,SHAP更能清楚的反映每个样本中各个特征的影响力,具有样本特异性,也能反馈出作用的正负性。 一个特征的shapley value是该特征在所有的特征序列中的平均边际贡献。
LIME
Local Interpretable Model-Agnostic Explanations(LIME)与模型无关,可以用于任何机器学习模型,通过扰动样本输入量化预测结果的变化来理解模型。
有时候可能不是自己的模型,无法更改,如果还想要可解释性,可以考虑LIME。即使对模型内部完全不清楚也能解释行为。
LIME的核心思想是:对一个复杂的分类模型(黑盒),在局部拟合出一个简单的可解释模型,例如线性模型、决策树等等。
将图像划分为多个超像素块(划分为像素太小了)每个像素块进行扰动,看对结果的影响。从而找出影响程度最大的几个超像素
不过缺点就是比较慢,因为相当于每次改变还要过一次模型
深度学习医学图像的可解释性
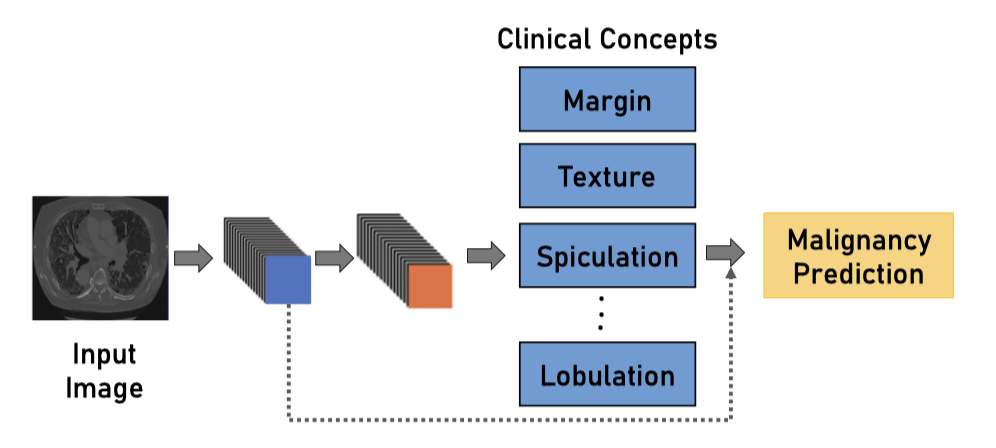
概念学习模型 Concept Learning Models
放射学家无法直接理解图像的深层特征,所以先从图像中预测高级语义特征(如临床概念),再使用这些可解释的概念进行最终预测。
不过缺点就是需要手动注释这些标签。
基于案例的模型 Case-Based Models
基于案例的模型适用于分类任务,它通过比较从图像中提取的特征和类别特异性原型。原型分类是可解释的,因为预测是通过输入和原型特征之间的相似性程度来判断的。
局限:容易受到噪声和压缩的影响,且难以训练。
反事实解释 Counterfactual Explanation
通过对原始图像施加最小扰动来最大程度地改变模型预测结果,从而能够发现关键区域和改变预测所需的重要变化。
反事实的图像基本是通过GANs或者扰动autoencoder的潜在空间来生成的。
局限:生成图像的分辨率是有限的。
概念因子 Concept Attribution
全局的解释,可以量化深层概念或放射学特征对预测结果的影响。
局限性:很难对深层的特征进行标注。
语言描述 Language Description
在预测的同时增加文本描述提供解释,不过增加了很多注释成本。
文本解释和预测一致
局限:结构化诊断报告需要更多注释,在测试过程中重复训练句子。
潜在空间解释 Latent Space Interpretation
潜在空间用于揭示数据中与临床知识相关的显著变异因素。在二维中可视化高维潜在空间,以识别相似性和异常值。
比如采用PCA、t-SNE等方式降维CNN的高维特征
局限:将高维特征空间投影到二维时的信息丢失。潜在空间中的相似性并不总是转化为人类可解释特征方面的相似性。
归因图 Attribution Map
通过突出显示模型认为重要的输入图像区域,可以提供事后解释。 Attribution Map可以理解为描述区域重要程度的热力图,反映的是注意力,和原图尺寸是一样的。
不过这种热力图反应的是作出贡献的程度,但是却没有反映如何为预测作出贡献。
比如分层相关性传播分层相关性传播(LRP),通过评估相关性得分生成热图,一层层计算每个神经元的贡献大小
CAM(Class Activation Mapping)
类激活映射(Class Activation Maps,CAM)在最后一个卷积层之后添加一个全局平均池层。然后将全局平均池层的输出线性组合以生成类预测。通过获取最后一个卷积层激活的加权和,获得每个类的CAM。不过使用CAM的网络不能有全连接层。
接上GAP全局平均池化然后softmax,就可以获得每个class的热图
GAP替换MLP,求每张特征图所有像素的均值。支持任意大小的输入。
最后一层生成了和目标类别数量一致的特征图,经过GAP再经过softmax得到结果,这样就给每个特征图赋予了意义。
每一个类别C、每个特征图k都有一个对应的权重$w^c_k$
训练完后,对于每一个类别C,可以加权所有的特征图合成针对某个类别的热力图,从而看出重要的地方。
Grad-CAM
CAM的缺点在于,他需要修改原模型的结构,需要重新训练模型
Grad-CAM和CAM的最大区别在于求权重$w^c_k$的过程,Grad-CAM通过梯度的全局平均来计算权重,数学推导和CAM的权重是等价的。
第k个特征图针对类别C的权重: $$ \alpha_{k}^{c}=\frac{1}{Z} \sum_{i} \sum_{j} \frac{\partial y^{c}}{\partial A_{i j}^{k}} $$
Z是特征图像素个数,$y^c$是对应类别的分数(softmax之前的值),$ A_{i j}^{k}$是第k个特征图的(i,j)位置的像素值,得到所有权重后,加权求和即可得到热力图:
$$ L_{G r a d-C A M}^{c}=\operatorname{ReLU}\left(\sum_{k} \alpha_{k}^{c} A^{k}\right) $$
局限:没有提供相关区域如何对结果作出贡献,多个类可能高亮相同的区域。
解剖先验 Anatomical Prior
任务特定的结构信息被纳入网络的设计过程中。
局限:可能需要专业的临床知识,但解剖学知识不能用于所有问题。
内部网络表示 Internal Network Representation
将CNN中不同过滤器学习到的特征的可视化。
局限:不同的过滤器学会识别的结构和模式在医学图像中很难解释。
可解释性评估方式
分为基于应用的、基于人工的、基于功能的共三种
参考:
- Transparency of Deep Neural Networks for Medical Image Analysis Review of Interpretability Methods
- https://zhuanlan.zhihu.com/p/258988892
- https://zhuanlan.zhihu.com/p/326586020
- https://www.jiqizhixin.com/articles/2019-10-30-9