介绍
GFS,即Google File System,谷歌文件系统。 它是一种能够用于大型密集型数据的可拓展的分布式文件系统。(大型存储系统),它对于廉价硬件提供了容错机制;对于大量客户的情况能有高表现。
GFS的设计是由实际的应用程序负载和技术环境驱动的,与传统的文件系统的一些假设不一样。
设计
一些假设
- 软硬件故障是常态而不是例外
- 文件是巨大的(多GB级也是普遍的)
- 负载包括大的流式读取和小的随机读取
- 负载还包括大的顺序的append写入
- 大多数文件是通过append而不是overwrite来改变的,一旦写入,就只能读取,而且是顺序读
- 放宽了一致性,从而极大简化了文件系统
- 引入了原子的追加写,可以并发的追加
- 高的持续带宽比低延迟更重要
一般用append,GFS对其一致性有保证,最好不用write
接口
接口方面支持通用的create、delte、open、close、read、write。并且还有snapshot和append操作。 snapshot以低成本创建文件或者目录的副本,append允许多个客户端并发的追加同一个文件,保证原子性。 对于实现多路合并以及生产者-消费者模型很有用。
架构
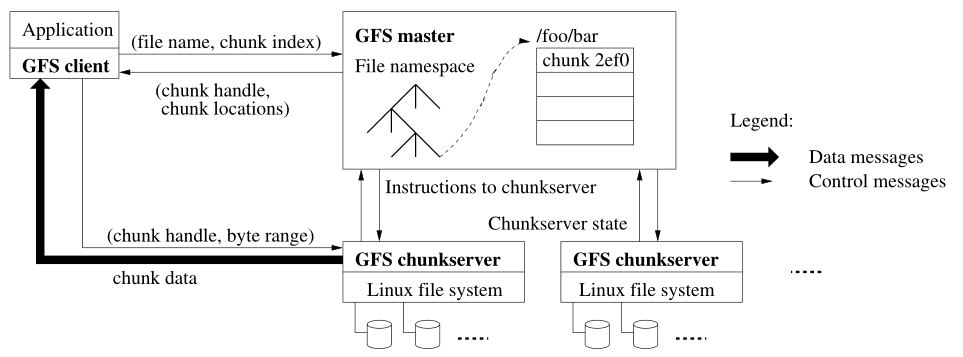
一个GFS集群由一个master结点和多个chunk sever构成,并被多个客户端访问。它们通常都是普通的Linux机器。
GFS把文件切割为若干固定长度的Chunk块并存储,每个块的大小是64MB,在创建块时,对于每一个Chunk,master还会为其分配一个64位的全局唯一的Handle句柄。为了保证Chunk的可用性,每个块都会被复制到多个chunk server上,默认存储三个副本。
master维护所有文件系统的元数据,包括namespace、访问控制信息、从文件到chunk的映射、以及块的当前位置。它还控制系统范围内的活动,比如chunk的租约管理、孤立chunk的gc、chunk server之间的chunk迁移。master定期与chunkserver维持心跳通信,给chunkserver指令以及接受它们的状态。客户端和chunkserver都不需要缓存文件数据,从而简化系统,唯一可能要缓存的可能就是客户机会缓存一下元数据。
Single Master
设立一个master可以极大的简化系统的设计,可以很方便地进行全局信息的管理。然而单一的master很容易成为系统的瓶颈,所以只能让其尽可能少的参与读写。客户端从来不从master中读写文件数据,而是向master询问它需要的文件在哪,然后访问这些chunkserver去进行文件交互。
下面解释一下交互过程,首先客户端借助固定的块大小,将文件名和偏移量转换为块索引,然后向master发送包含文件名和块索引的请求,master返回一个chunk句柄和副本的位置。接下来客户端会向其中一个(往往是最近的)存储着该文件副本的chunkserver发送请求,之后对同一个chunkserver的交互不需要master的参与。事实上客户端通常一次会请求多个块。
Chunk Size
选择的是64MB,比典型文件系统的块大得多,相对于小的chunk size,更大的chunk size的优势在于:
- 减少客户端请求的chunk数量,减少客户端与master的交互需求。
- 大的chunk可以让客户端执行很多操作,通过较长时间与chunkserver的持续的tcp连接来减少网络开销
- 减少了chunk的个数,从而减少了存储在master的元数据的大小
当然,大的chunk size也有缺点:
- 可能会出现更多客户端访问一个chunk从而导致这个chunk成为hot spots。一般来说还好,不过如果某个可执行文件被写入了某个chunk,然后在数百台机器上同时启动,那个chunkserver就很容易超载。一个解决方法是将可执行文件复制更多份,并使批队列系统错开启动时间。还有一个解决方法是允许客户机从其他客户机读取数据。
Metadata
元数据包含文件和chunk的namespace、从文件到块的映射、以及每个chunk副本的位置,所有的元数据都存储在master的内存中。前面两个也通过日志的方式存储在本地磁盘中,实现持久性存储,顺带也复制在远程机器上备份。这个主要是保证即使master崩溃了也不会出现不一致。 至于chunk副本的位置,master并不会持久地存储,而是在master启动的时候对每个chunkserver进行轮询,或者在新的chunkserver加入集群时询问。
- 内存中的数据结构 元数据存储在内存中,所以访问起来很快。 master还会在后台周期性的扫描整个状态,用于实现gc、chunkserver故障时的重新复制、块迁移来平衡负载等。
可能会认为说元数据存在master内存中,整个系统的容量会受到master内存的限制,实际上chunk由于比较大,个数不会那么多,master也只需要存每个chunk的不到64字节的元数据,所以还好。
-
chunk位置 前面说了master通过启动时的轮询获得信息,并且还会保持一个心跳来监听各个chunkserver的状态。 由于集群很大,如果在master上持久化在本地存储chunk副本位置,之后变动会很多(改名、宕机、重启等),并且实际上chunkserver才是对chunk有着最终决定权,在master上维护一个一致性的视图是没有意义的。
-
操作日志 操作日志包含了元数据发生重大变化的历史记录,是GFS的核心。它是元数据的唯一持久性记录,也作为定义并发操作顺序的逻辑时间线。操作日志需要被可靠地存储。 如果系统崩了,master就会重新执行log来恢复GFS,所以log也不宜过大,以免启动时间过长。会先找到重载的checkpoint然后执行之后的日志记录。检查点是一种类似B树的紧凑形式,加快恢复速度。
一致性模型
GFS并不保持一个严格的一致性,而是保持一个相对宽松的一致性
- GFS保证的 命名空间是原子的,保证操作日志是全局的顺序正确的。
数据更改之后的文件区域的状态:
文件数据更改之后,会定义一个region,其状态取决于变化的种类(write/append)、是否并行、成功还是失败。
如果它是一致的,客户端会看到变化写入的内容。 如何区分已定义区域和未定义区域。
在一次成功的顺序变化后,GFS会:
- 在chunk的所有副本上以相同的顺序应用这些变化
- 使用chunk版本号来检测副本
应用程序应当append而不是write。
系统交互
描述客户端、master、chunkserver如何进行交互,完成数据更改、原子追加和快照。
租约和数据更改顺序
数据更改(mutations)就是改变chunk的内容或者元数据的操作,比如write或append。数据更改在chunk副本上执行。 使用租约(leases)来维持副本之间的一致的变化顺序。master会将租约授权给其中一个副本,称之为该chunk的主服务器(primary)。主服务器会为这个chunk的所有更改进行顺序排序,其余的所有副本都遵守这个顺序进行更改。 租约机制的目的也是减少master的管理开销,租约的初始时间是60s,不过主要chunk发生了改变,primary就可以向master请求拓展,这些请求被承载在心跳信息上。
下图是写操作的控制流与详细的步骤
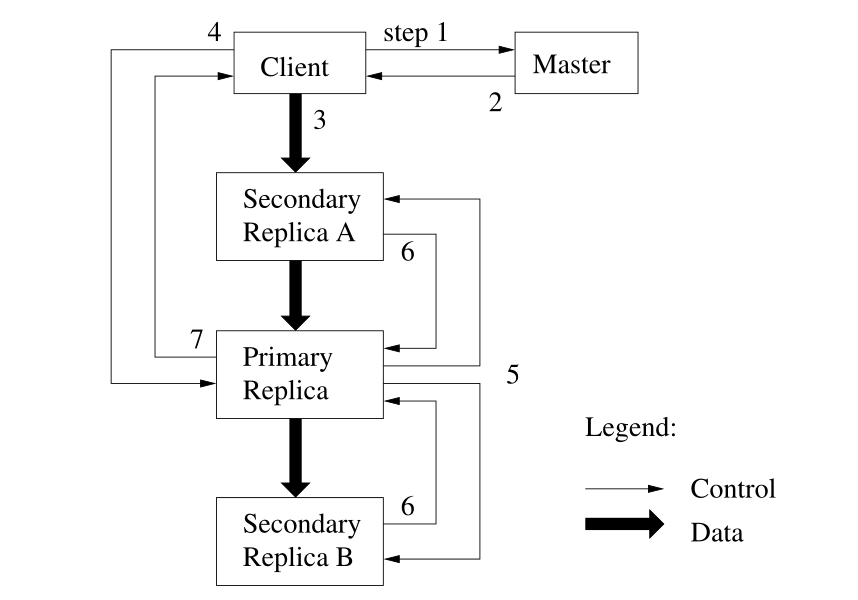
- 客户端询问master哪个chunkserver持有当前chunk的租约,以及其他副本的位置。如果没有服务器有租约,master就选择一个副本服务器分给它租约
- 服务器返回primary和副本chunkserver的位置,客户端把它们存在缓存中,如果未来短期内再次访问就不需要请求master。除非primary不可达或者primary告知客户端它没有租约了。
- 客户端知道副本位置后,将数据push进所有的副本中,可以按照任何顺序。每个chunkserver将数据存储在一个内部的LRU缓存中
- 一旦所有的副本都确认接受到了数据,客户端就向primary发送写请求,标识了之前push的数据,primary会分配序列号给这些mutations,提供必要的序列化
- primary将写请求转发给各个备用副本,每个备份副本按照序列号执行更改
- 备份副本回复primary表示已经完成了操作
- primary响应客户端,任何遇到的错误也会报告
数据流
数据流和控制流解耦,为了充分利用每台机器的带宽,数据被线性的沿着chunkserver链进行推送,而不是分布在拓扑网络中,这样每台机器的带宽就可以被充分利用,每台机器将数据转发到网络拓扑中“最近的”没有接收到它的机器。(感觉像Prim算法)
原子追加
GFS提供了原子追加(atomic record appends)操作。
传统的写操作需要提供数据和偏移量,如果出现并行的情况就很可能会出现来自多个客户端的碎片。
在GFS中,客户端只提供数据,GFS会选择偏移量并将其返回给客户端,类似于Unix的O_APPEND。
大量使用record append,如果是传统的写操作,为了保持一致性就只能使用分布式锁,代价很昂贵。
Snapshot快照
类似AFS,使用标准的copy-on-write技术实现快照。
Master操作
master的任务:
- 执行所有namespace相关的操作
- 管理系统的chunk副本以及与之相关的一些操作
namespace的管理和锁定
GFS没有传统文件系统的per-directory数据结构。也不支持alias。
gc
文件被删除之后,不会立即回收资源,而是先重命名为包含删除时间戳的隐藏文件,如果隐藏文件存在超过三天,就删除它们。在此期间,这些文件可以被恢复。 内存元数据也会被删除,切断和所有chunk的联系,在和master的心跳中,chunkserver报告自己的chunks,master会返回不出现在namespace里的,chunkserver接受到后可以删掉这些chunk。
容错性与诊断
高可用性
通过两种简单而有效的策略来保持整个系统的高可用性:快速恢复和复制
-
快速恢复 master和chunkserver都可以在几秒内启动
-
chunk复制 默认是复制3份
-
master复制
操作日志和检查点被复制到多台机器上