拜占庭将军问题
拜占庭将军问题是分布式领域最复杂的一个容错模型,较好地抽象了分布式系统面临的共识问题。
假如你是一位拜占庭的将军,需要与其他几个国家的军队做沟通,而信使可能会被杀,可能会被替换,可能某国军队会传递错误信息等等,抽象出来的问题就是,如何在可能有错误发生的情况下,让多个节点达成共识,保持一致。
拜占庭将军是最困难的一种情况,因为会存在恶意节点行为行为,在某些场景(比如数字货币区块链)只能使用拜占庭容错算法(Byzantine Fault Torerace,BFT),常见的拜占庭算法有口信消息型算法、签名消息型算法、PBFT算法、PoW算法等。
在计算机分布式系统中,最常使用的还是非拜占庭容错算法,也就是故障容错算法(Crash Fault Tolerance,CFT),解决的是分布式系统中存在故障,但不存在恶意节点的场景。常见的算法有Paxos算法、Raft算法、ZAB协议等,这些协议之后都会讲解。
不过对于恶性的情况,一般只在区块链中出现,算法有PBFT、PoW等。但是我并没有打算涉足区块链相关的研究,所以这些算法不在讨论范围之内。
共识算法的概念
共识算法就是用来达成一致性的方法。
需要满足三个条件:
- Termination:保证算法最后可以做出决定,不能是无限循环的
- Validity:最终决议一定来自于其中一个参与的节点
- Agreement:算法完成时,所有节点一定会做出相同的决定
FLP定理:完美的共识算法不存在。在非同步的网络环境中,就算只应付一个节点故障,也没有一个共识算法能保证完全正确。
一般的共识算法分为两类:
- Symmetric, no leader
所有的节点地位等同,client可以向每一个server发送请求
- Asymmetric, leader based
任一时刻只会有一个leader,leader处理client的请求,其余server只接受leader的决策,client只可以向leader发送请求。
Paxos算法
Paxos算法是分布式共识算法的元老,目前最流行的分布式算法都是基于Paxos改进的,所以不得不提。
兰伯特Lamport提出的Paxos包含两个部分: 一个是Basic Paxos,描述的是多个节点之间如何就一个value达成共识; 一个是Multi-Paxos,描述的是执行多个Basic Paxos实例,为一系列value达成共识。 这一节只说Basic Paxos,Multi-Paxos下一节
系统角色
提议者(Proposers):向系统里的其他节点提出v=C,希望大家达成共识。
接受者(Acceptors):不发起proposal的节点,接受Proposers的提议。
学习者(Learner):不参与投票的过程,被告知投票的结果,接受达成的共识存储保存数据。
算法流程
分为两个流程:
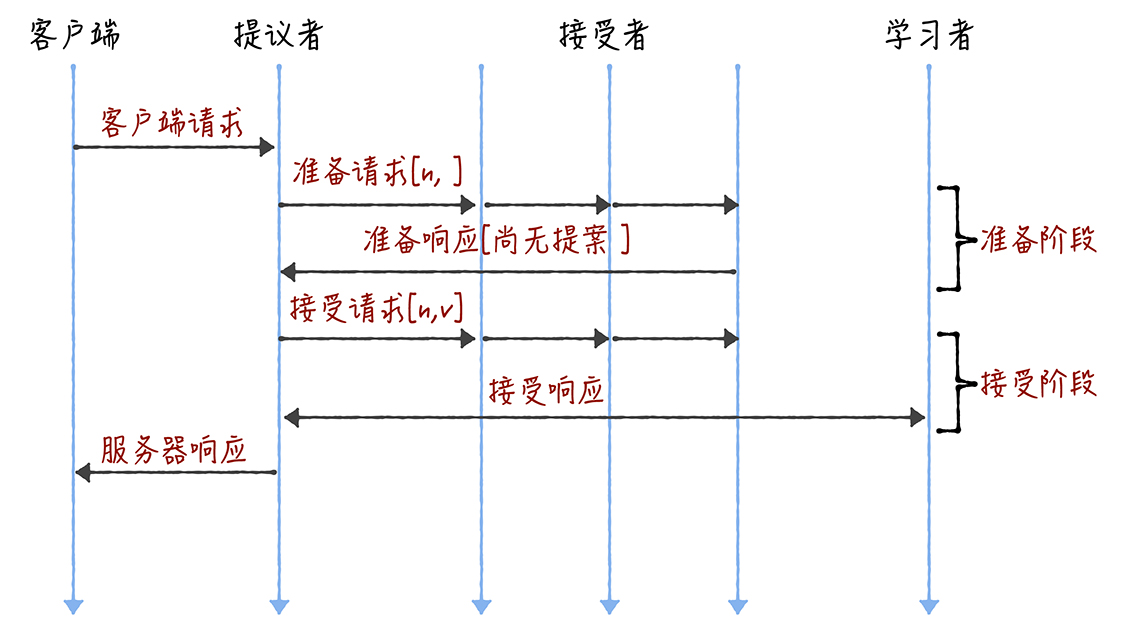
第一步:准备阶段
在提出提案之前,先得到超过半数节点的回应,也就是有半数以上的节点愿意聆听这个Proposer。假设这次要发送的数据是v
具体的过程:Proposers向所有节点发送Prepare(n),n包含了一些元信息,可以比较大小,Acceptors接收到后,与这一轮从其他Proposers里收到的最大的提议N比较。
准备阶段只需要发送n即可,不需要发送v。
如果$n<N$,也就是目前的这个提议的n比这一轮已有的最大的N还小,直接无视这个提议。
否则,就认为当前提议更好,如果此时已经发送过了一个返回给之前最大的那个Proposer,就返回一个ack(n, (nx, vx)),n是这一次的n,nx是之前最大的那个Proposer的n,vx之前最大的那个Proposer的x。如果之前没接受过其他提议,就发送ack(n, (null, null))
第二步:接受阶段
Proposers等待过半的Acceptors返回后,对ack作出判断,如果里面有节点的ack返回的nx、vx不为空,就主动放弃,找出里面最大nx的vx,再发送accept(n,vx)给所有的Acceptors。
如果都为空的话,就传送accept(n,v)给所有的Acceptors。
Acceptors收到accept(n,v)后,不过可能还会收到prepare(n)
Paxos论文描述:

一些容易想错的地方,进行声明:
这里的n并不是具体的int,只是为了简单描述算法,实际上这里的n是一种数据结构,但是相互之间可以被比较,并且对于每个节点而言,它们的n必然不相同。 并不是说一个节点只能当Proposer、Acceptor、Learner中的一种,实际上,每个节点都同时具有这三种角色。 Basic Paxos只是对一个值形成决议,并不是多个值。
具体例子
举一个具体的例子,两个客户端作为提议者,n分别为1和5,v分别为3和7,有三个接受者。
- 准备阶段
提议者分别发送Prepare(n)给三个节点,假设说AB先接收到了客户端1的信息,C先接受到了客户端2的信息
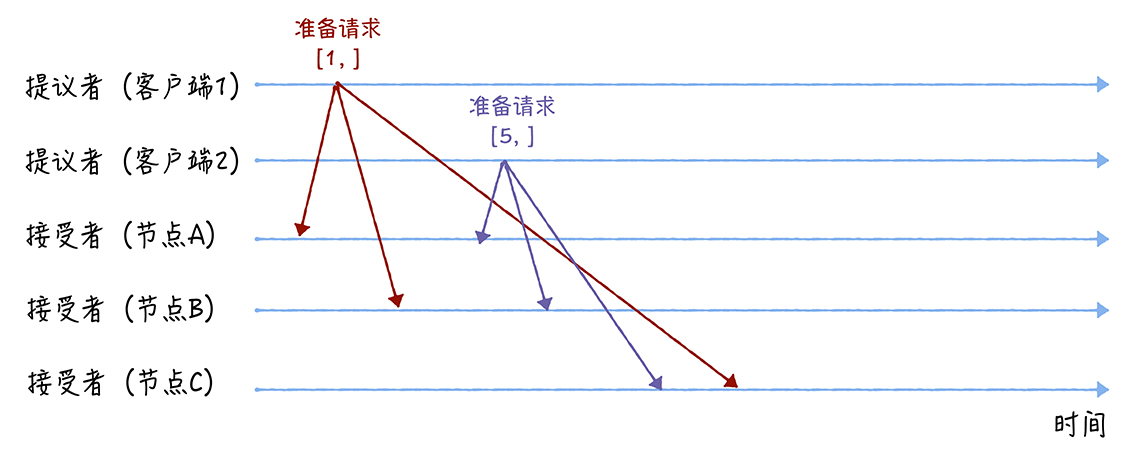
由于接受者之前没有提案(也可以认为目前的n是无穷小),所以接受到第一个提案后都进行响应,返回ack(n, (null, null))
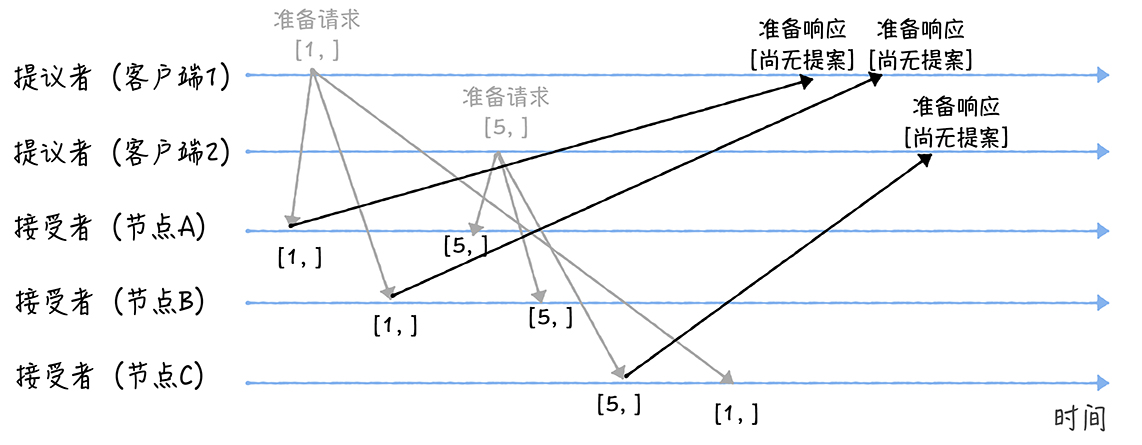
之后AB接受到客户端2传来的Prepare(5),5>1,所以会发送准备响应给2。C接受到客户端1传来的Prepare(1),1<5,直接无视该请求
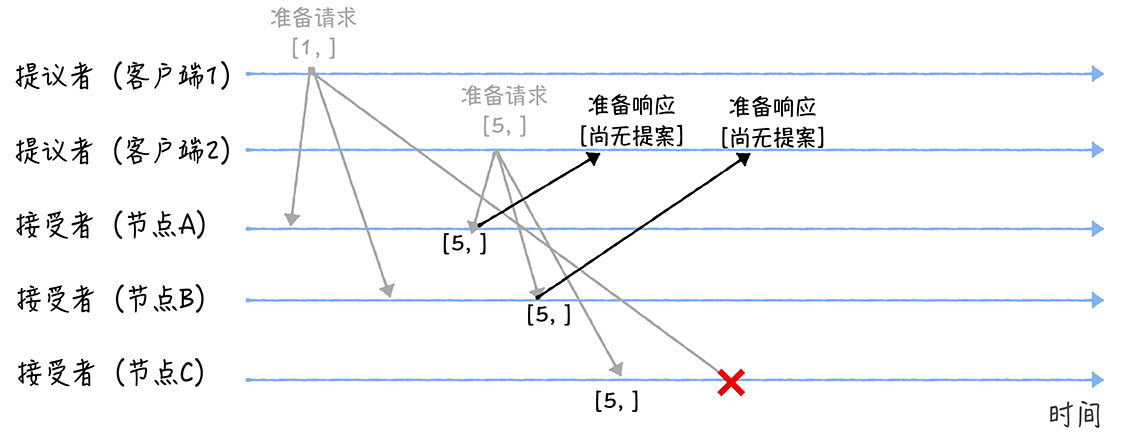
- 接受阶段
由于1、2都收到了多于半数的准备返回响应,并且返回的响应包含的之前最大提案号为空,所以会发送分别接受请求
accpet(1, 3)和accept(5, 7)
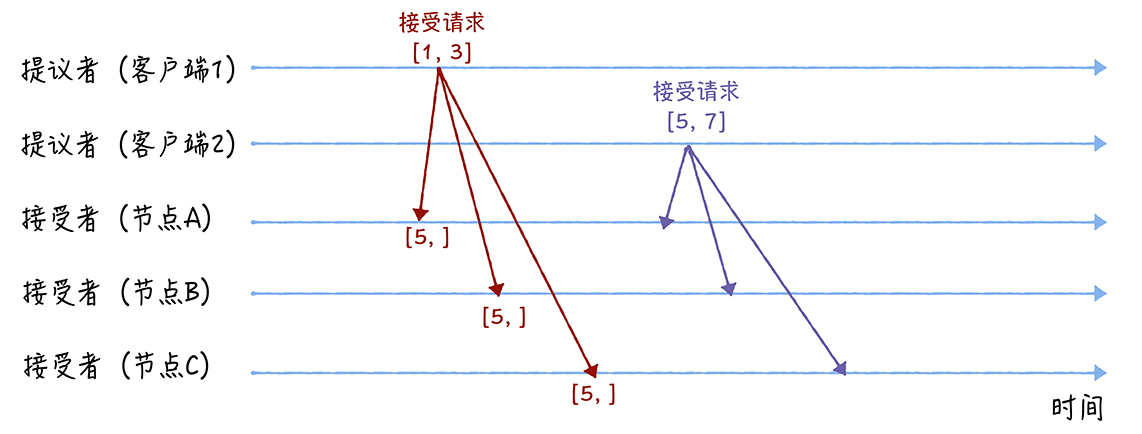
最后ABC接受到1的确认,由于之前承诺不再接受n小于5的,所以不会变。接受到5的确认后就修改为了5
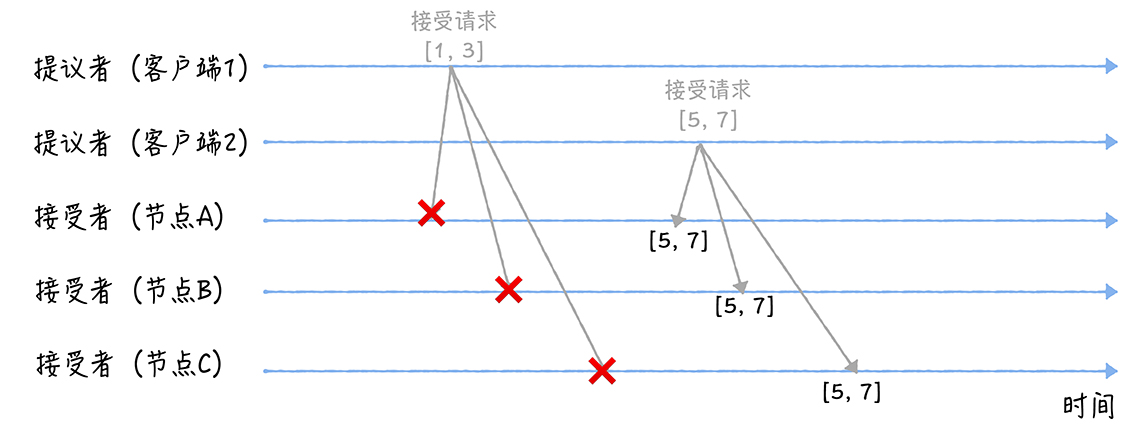
假设另一个例子,在某个顺序AB是n=5,v=7,C是n=1,v=3。此时有一个请求[9, 6],发送给ABC之后,准备阶段,由于9>5,ABC会接受,并返回
ack(n, (nx, nv)),具体是AB返回ack(9, (5, 7)),C返回ack(9, (1, 3)),那么客户端3由于接受到的返回不为空,就会判断之前最大的n,这里是5,对应的v是7,所以在接受阶段会发送accpet(9, 7)给所有节点。
可以参考这个视频:https://www.youtube.com/watch?v=UUQ8xYWR4do
Multi-Paxos
Multi-Paxos并不是一个具体的算法,而是一种思想。指的是基于Mulit-Paxos算法通过多个Basic Paxos实例实现一系列值的共识的算法。(比如Raft算法、ZAB协议等)
由于第一阶段收到大多数准备响应的提议者才能发起第二阶段,那么如果多个提议者同时提交提案,可能因为永远无法收到超过半数的准备响应而阻塞。(比如系统中有5个节点,有3个同时发起提案)。 另一个问题是两轮的RPC太消耗性能,也增加了延迟。
通过引入Leader(领导者)角色以及优化Basic Paxos来解决这两个问题。
Leader节点作为唯一的提议者,这样就不存在提议冲突的情况。
Leader的提案永远是最新的,所以省略掉准备阶段,直接开始接受阶段:
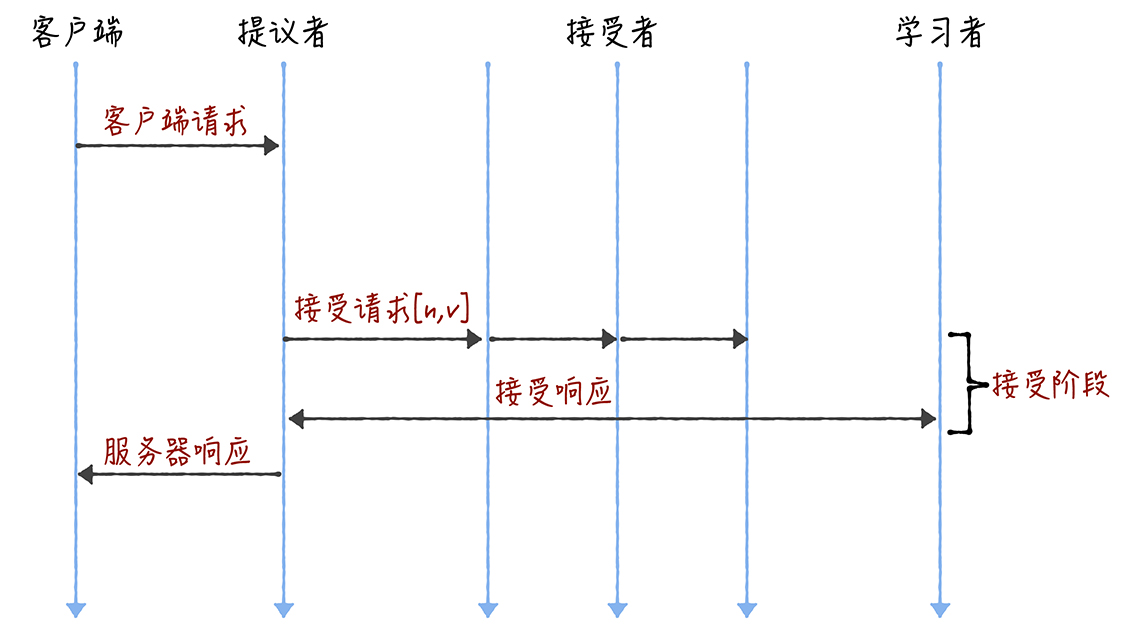
Chubby的Multi-Paxos实现
Chubby实现了闭源的Multi-Paxos,通过引入Leader节点。Leader是通过执行Basic Paxos投票产生的。 运行过程中会通过续租的方式延长租期,如果Leader故障,其他节点会选举出新的Leader。 所有的读和写操作也只能在Leader上进行:
- 写请求,Leader收到客户端的写请求,作为唯一的Proposer执行Basic Paxos将数据发给所有的节点来达成一致,半数以上的服务器接受了写请求之后,响应给客户端成功
- 读请求,很简单,Leader直接查询本地数据返回给客户端即可。
Chubby的ulti-Paxos实现的一些点:
- Leader本地的数据一定是最新的。
- 可以容忍$\frac{n-1}{2}$个节点的故障
Raft
Raft算法在Multi-Paxos的思想上进行了简化和限制,是最常用的一个共识算法,也是目前分布式系统的首选共识算法。包括Etcd、Consul等。
本质上来说,Raft算法是通过一切以领导者为准的方式,实现一系列值的共识和各节点的日志一致。
强烈推荐看一下这个可视化的Raft,可以加深理解:http://thesecretlivesofdata.com/raft/
Leader选举
服务器节点的状态分为三种:Leader(领导者)、Follower(追随者)、Candidate(候选人),其中Leader有且只有一个。
Leader:系统的核心角色,负责处理写请求、管理日志复制和不断与其他节点维持心跳,告知节点Leader存活,不要选举 Follower:普通群众,接受和处理来自Leader的消息,如果Leader心跳超时就主动站出来变成Candidate Candidate:候选人,向其他节点发送RequestVote的RPC消息,通知其他节点投票,一旦获得了多数投票就晋升为Leader
Raft算法实现了随机超时时间,每个节点等待Leader的心跳超时时间随机。
初始时没有Leader,都是Follower,所有节点听不到Leader心跳,超时时间最小的节点首先称为候选者。 它会增加自己的任期编号,给自己先投一票,然后发送RPC请求其他节点投票。 其他节点收到RPC投票消息之后,如果还没有称为候选者,也还没投票的话,就会去投一票,同时增加自己的任期编号。 如果在选举超时时间内获得了大多数的选票,就晋升为Leader。
关于RPC Raft算法总共有两类RPC,一个是请求投票RequestVote,一个是日志复制AppendEntries
关于timeout 每个节点的等待时间有两种: ① 一个是election timeout,也就是从上一次Leader心跳开始算,如果过了这个timeout还没听到心跳,就自己称为Candidate,这个timeout一般是150-300ms ② heartbeat timeout
关于任期 任期由单调递增的数字(任期编号)标识 何时加1?Follow发现Leader心跳超时,将自己任期+1,并发RPC 何时更新? ① 跟随者接受到包含任期的RPC请求后,发现任期比自己的大,就更新自己的任期为更大的任期。 ② Leader或者Candidate发现自己的任期编号比其他节点小,会立即降为Follower
如果一个节点收到一个包含任期编号比自己小的RPC请求,会直接无视。 任期编号相同时,日志完整性高的Follow会拒绝投票给日志完整性低的Candidate
做法就是RequestVote RPC也会包含Candidate自己最后一个log entry的index和term,如果收到RequestRPC的节点发现这个Candidate最后一个log的term小于自己的term,或者term相等的时候index小于自己的index,那么就不会投票给它。这一策略保证了Leader一定拥有最完整的log entries
可能会出现多个Candidate同时发起投票请求,这样的话瓜分选票会导致无法选出半数以上的票,不过Raft通过随机超时时间解决了这一问题,把超时时间都进行了分散。这里的超时时间有两种,一个是Follower和Leader维持的心跳超时,一个是等待选举超时的时间间隔。
当然还有可能出现的极限情况,比如说刚好两个Candidate各拿到了一半的票,那么陷入阻塞,此时这两个Candidate还会有随机timeout,如果时间过了就重新发送RequestVote
几个注意的点:
只有日志最完整的节点才能当Leader,Raft中,日志必须是连续的
日志复制
日志项包含指令、索引值、任期编号等。
第一阶段,Leader通过日志复制AppendEntries,将日志项复制到集群的其他节点上,如果收到了大多数的“复制成功”消息,就把提交这条日志,并返回成功给客户端,否则会返回错误给客户端。
一开始只是保存日志到本地,比如客户端提交一条
SET x = 5,Leader会先把这条写在日志里,不会修改x的值,等到多数节点返回成功之后才会执行这条指令,把x设为5。
AppendEntries RPC在每个heartbeat都会发送
Leader不需要发送消息来告知其他节点提交日志项,Leader的日志复制RPC和心跳包含了当前最大的将被提交的日志项。从而将二阶段简化为一阶段。
具体的过程为:
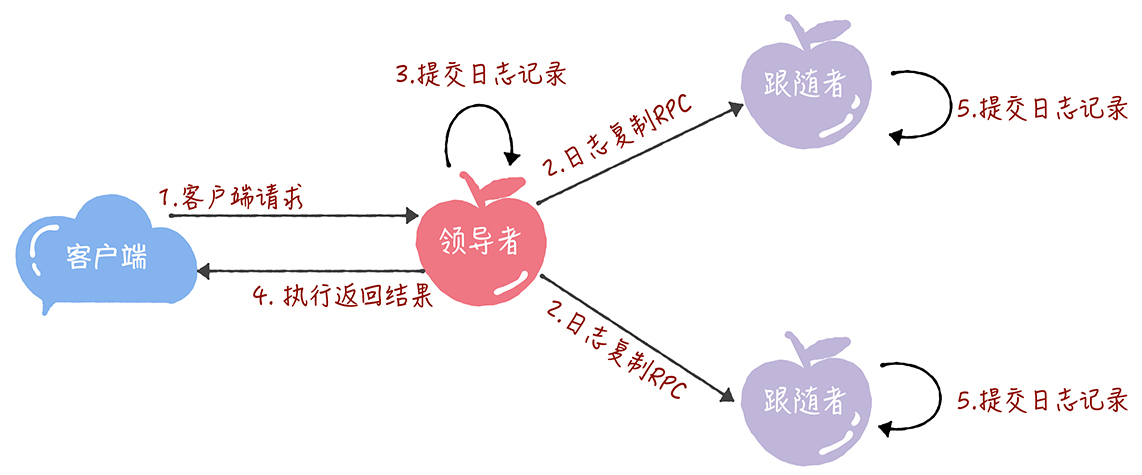
- 客户端提交一条写请求
- Leader将其存在本地日志上,然后给各个Followers发送日志复制AppendEntries RPC,
- 如果有多数的Follower返回成功,Leader就将日志进行提交
- Leader将执行的结果返回给客户端
- 之后如果Follower收到新的日志复制RPC或心跳,发现自己有日志项没提交,就进行提交
日志一致性的保证: Leader的日志必然是完整的,以Leader的日志为准来协调各个节点的日志。
首先通过AppendEntries RPC的一致性检查来找到自己与Follower相同日志项的最大索引值,之前的日志Follower和Leader一致,之后的就不一致了,然后Leader强制Follower覆盖不一致日志。
引入两个变量: PrevLogEntry:当前要复制的日志项的前一项的索引值,下面例子中为7 PrevLogTerm:当前要复制的日志项的前一项的任期编号,下面例子中为4
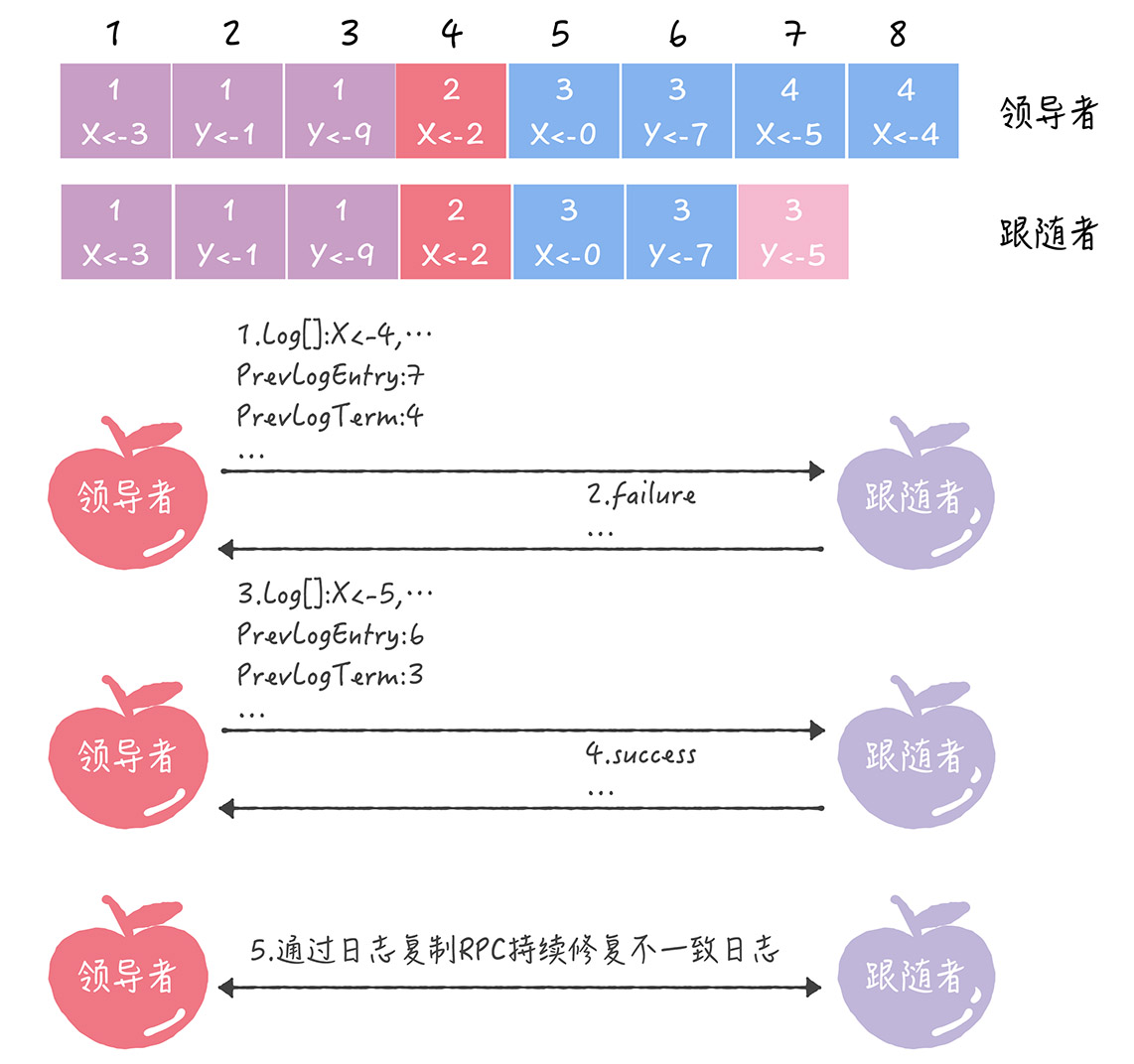
- Leader发送AppendEntries RPC,包含当前任期编号4、PrevLogEntry=7、PrevLogTerm=4,
- Follower发现自己的索引中没有这一条,返回Failure
- Leader递减要复制的日志项的索引,发送PrevLogEntry=6、PrevLogTerm=3
- Follower能在本地日志找到这一项,返回Success
- Leader知道了自己与该Follower的相同日志的最大索引,复制并更新覆盖索引值之后的日志项。
为什么要上一条?因为这一条的话刚写,必然不一样,如果Follower一直和Leader一致,Follower是有Leader的上一条的,但是必然没有Leader新的一条,所以Leader如果从最新的一条发RPC,每一个节点都必然返回Failure,然后递减,非常浪费RPC。 由于大部分节点是能同步日志的,所以第一次都会返回Success,然后Leader把新的一条复制过去即可,对于第一次Failure的个别节点,才会递减找到相同的最大索引值。
成员变更
在成员进行变更的时候,如何避免出现大于一个的Leader? 比如出现了分区,节点被分为了多个簇,簇与簇之间无法沟通,那么每个簇内都会有一个Leader。
如果只是为了解决不出现多个Leader的情况,最暴力的方式就是节点全部关闭然后再重新启动,这样投票只会有一个Leader,但是这段时间系统会瘫痪,明显不合理。 最常用的方法是单节点变更,也就是每次只变更一个节点。
比如当前集群配置为[A, B, C],现在往里面加入[D, E],一个一个加,先加D进去: 首先Leader向D同步所有数据,然后Leader更新自己的配置为[A,B,C,D],将包含新配置的日志项提交到本地状态机,完成单节点变更,之后E加入也一样。 通过单节点变更,可以保证系统只有一个Leader。
可以看一下Raft作者讲的: https://www.youtube.com/watch?v=vYp4LYbnnW8
总结
以这张图进行总结:
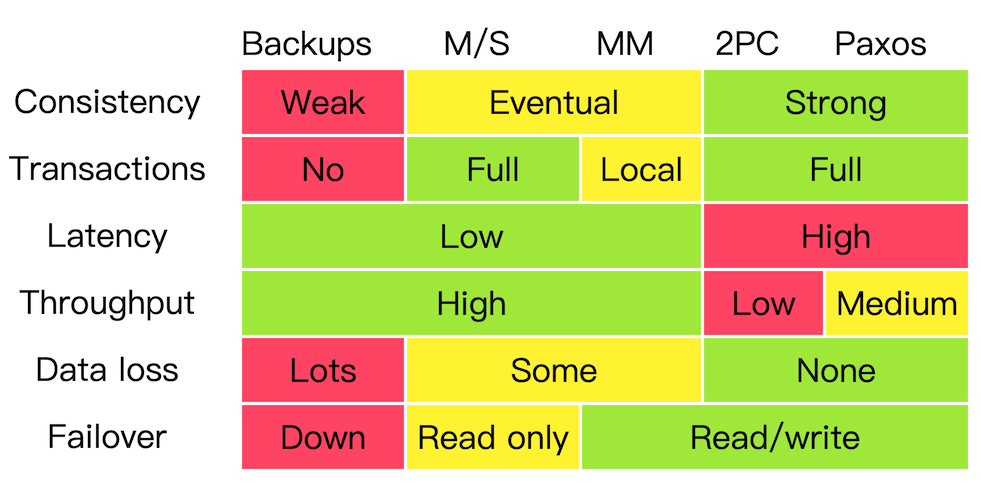
对于上述共识算法进行比较:
- Backup,简单备份
比如mac的time machine。 首先对于Consistency一致性,是无法保证的,一旦改变当前的文件,备份的旧版本和目前的会不一致。 Transaction事务也只能是weak。 Latency(时延)低、Throuput(吞吐量)高,因为读写的时候不需要运行协议,直接读取即可。 Data loss,如果没备份完,系统失效了,那最新的资料会遗失。 Failover 故障恢复,系统恢复的这段时间系统是不能工作的。
- Master/Salve 主从模式
读写请求都在master上进行,master将更新 的数据写到slave上。类似Dropbox。
Consistency:可以实现最终一致性 Transactions:Master支持完整事务 Latency、Throuput:读写的时候都直接在master上完成,所以低时延、高吞吐。 Data loss:可能造成数据丢失 Failover:恢复的时候slave还是可以提供read
- Master/Master
Leaderless模式,每一个节点都可以接受读写请求。比如DynamoDB。
Consistency:可以实现最终一致性 Transactions:只能本地支持 Latency、Throuput:低时延、高吞吐。 Data loss:可能造成数据丢失 Failover:仍能正常运作
- 2PC
二阶段模式
Consistency:强一致性 Transactions:支持完整事务 Latency、Throuput:因为每次都需要两阶段,比较差 Data loss:只要写入后资料达成一致就不会丢失 Failover:仍能正常运作
- Paxos & Raft
虽然表中没有raft,实际上raft和paxos也差不多。 Paxos可以认为是优化2PC之后的最优解。
Consistency:强一致性 Transactions:支持完整事务 Latency、Throuput:需要半数达成一致,相对差一点 Dataloss:只要写入后资料达成一致就不会丢失 Failover:只要有半数的节点存活就可以正常运行。
参考: