想对实验室的服务器搭建监控系统进行外部网页监控,目前比较主流的选择就是Prometheus + Grafana,先看最终效果:
服务器常规性能监控:
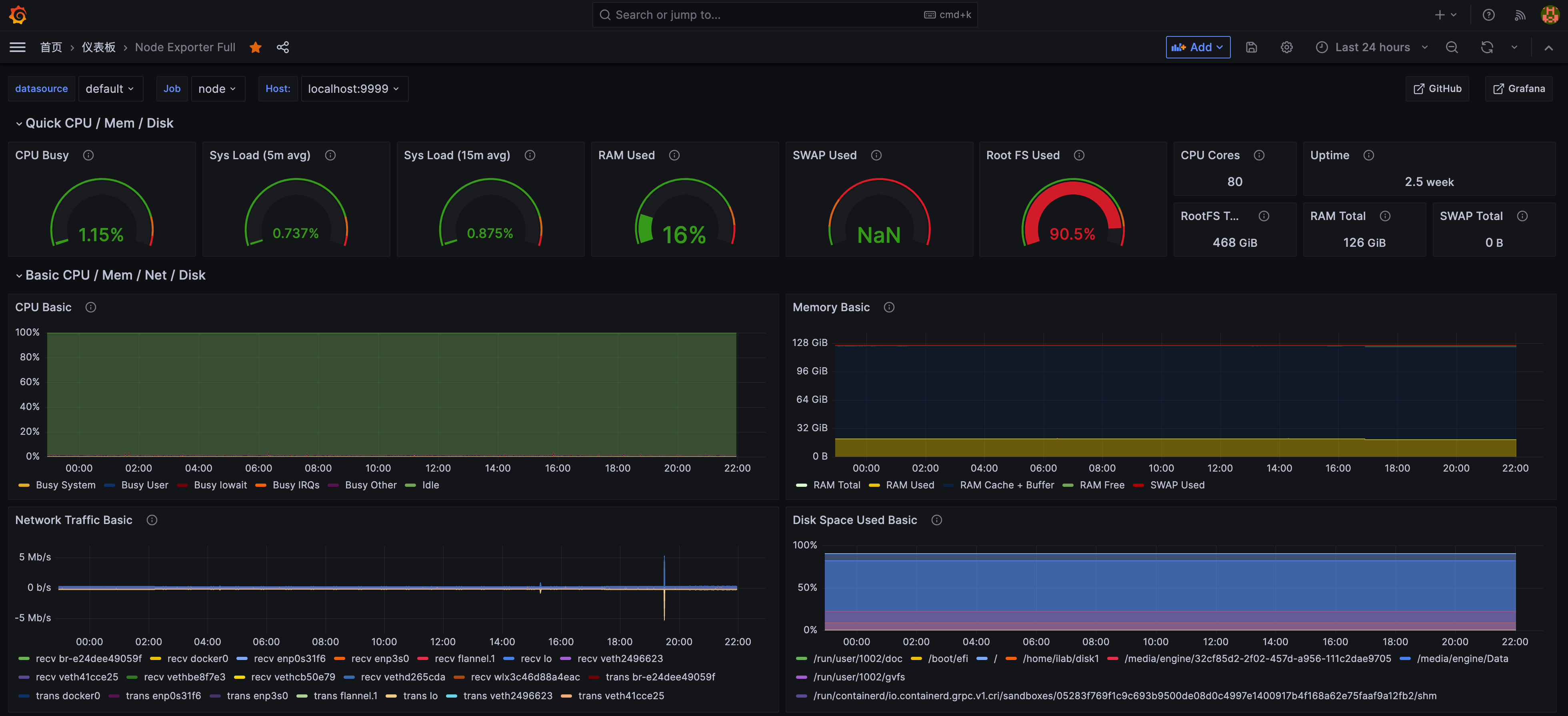
GPU监控:

Docker监控:

直接apt-get install可能会装比较老的版本,需要装稍微新一点的版本,比如2.40.6,所以这里我们手动下载安装。当然,这里用Docker也可以。
1
2
3
4
|
$ wget https://github.com/prometheus/prometheus/releases/download/v2.40.6/prometheus-2.40.6.linux-amd64.tar.gz
$ tar -zxvf prometheus-2.40.6.linux-amd64.tar.gz -C .
$ cd prometheus-2.40.6.linux-amd64
$ sudo cp prometheus promtool /usr/local/bin/
|
配置一下prometheus.yml,这里其实可以配置很多台监控,加到targets后面就行
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
...
scrape_configs:
- job_name: 'prometheus'
scrape_interval: 5s
scrape_timeout: 5s
# Prometheus的端口
static_configs:
- targets: ['localhost:9090']
# 这里提前把后面几个指标收集器都提前写了
- job_name: node
static_configs:
- targets: ['localhost:9999']
labels:
instance: ilab-Precision-7920-Tower
- job_name: gpu
static_configs:
- targets: ['localhost:9835']
labels:
instance: ilab-Precision-7920-Tower
- job_name: docker
static_configs:
- targets: ['localhost:8082']
labels:
instance: ilab-Precision-7920-Tower
|
1
|
$ sudo vim /etc/systemd/system/prometheus.service
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
[Unit]
Description=Prometheus
Documentation=https://prometheus.io/
After=network.target
[Service]
Type=simple
User=root
WorkingDirectory=/usr/local/bin
ExecStart=/usr/local/bin/prometheus --config.file=/home/engine/docker/prometheus/prometheus.yml --web.enable-lifecycle
[Install]
WantedBy=multi-user.target
|
1
2
3
|
$ sudo systemctl daemon-reload
$ sudo systemctl enable prometheus
$ sudo systemctl start prometheus
|
1
2
3
4
5
6
|
$ prometheus --version
prometheus, version 2.40.6 (branch: HEAD, revision: e1506e7be89e4ce346851bf6bd2b024b70fb7cb1)
build user: root@f4224a878a14
build date: 20221209-12:48:27
go version: go1.19.4
platform: linux/amd64
|
我们要收集的包括:基础指标(CPU、内存、硬盘等)、GPU指标、Docker指标
Node Exporter可以监控CPU、内存、磁盘等各项性能指标
定时检测服务器各项状态的收集器
1
2
3
4
|
$ curl -OL https://github.com/prometheus/node_exporter/releases/download/v1.5.0/node_exporter-1.5.0.linux-amd64.tar.gz
$ tar -zxvf node_exporter-1.5.0.linux-amd64.tar.gz -C .
$ cd node_exporter-1.5.0.linux-amd64
$ sudo cp /node_exporter /usr/local/bin/
|
1
|
$ sudo vim /etc/systemd/system/node_exporter.service
|
配置systemed,可以换到其他端口,我切到了9999
1
2
3
4
5
6
7
8
9
10
|
[Unit]
Description=Node Exporter
After=network.target
[Service]
Type=simple
ExecStart=/usr/local/bin/node_exporter --web.listen-address=":9999"
[Install]
WantedBy=multi-user.target
|
1
2
3
|
$ sudo systemctl daemon-reload
$ sudo systemctl enable node_exporter
$ sudo systemctl start node_exporter
|
1
2
3
4
5
6
|
$ node_exporter --version
node_exporter, version 1.5.0 (branch: HEAD, revision: 1b48970ffcf5630534fb00bb0687d73c66d1c959)
build user: root@6e7732a7b81b
build date: 20221129-18:59:09
go version: go1.19.3
platform: linux/amd64
|
由于实验室服务器很多都有GPU,需要通过nvidia_gpu_exporter进行GPU的指标收集
一般来说node exporter可以监控大部分的信息,但是gpu需要额外的监控
1
2
3
|
$ wget https://github.com/utkuozdemir/nvidia_gpu_exporter/releases/download/v1.2.0/nvidia_gpu_exporter_1.2.0_linux_x86_64.tar.gz
$ tar -zxvf nvidia_gpu_exporter_1.2.0_linux_x86_64.tar.gz -C .
$ sudo cp node_exporter /usr/local/bin/
|
1
|
$ sudo vim /etc/systemd/system/nvidia_gpu_exporter.service
|
1
2
3
4
5
6
7
8
9
10
|
[Unit]
Description=Node Exporter
After=network.target
[Service]
Type=simple
ExecStart=/usr/local/bin/nvidia_gpu_exporter
[Install]
WantedBy=multi-user.target
|
1
2
3
|
$ sudo systemctl daemon-reload
$ sudo systemctl enable nvidia_gpu_exporter
$ sudo systemctl start nvidia_gpu_exporter
|
默认监听9835端口,也不用修改了。
如果想监控Docker的状态,则需要配置cAdvisor (Container Advisor) ,它可用于对容器资源的使用情况和性能进行监控。
用docker一键部署,这里映射到8082:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
sudo docker run \
--restart always \
--volume=/:/rootfs:ro \
--volume=/var/run:/var/run:ro \
--volume=/sys:/sys:ro \
--volume=/var/lib/docker/:/var/lib/docker:ro \
--volume=/dev/disk/:/dev/disk:ro \
--publish=8082:8080 \
--detach=true \
--name=cadvisor \
--privileged \
--device=/dev/kmsg \
songtianlun/cadvisor:v0.46.0
|
前往http://localhost:9090/targets即可查看到,如果是无GUI的server,可以穿透之后访问frp server对应的ip和端口

由于我们最后要用内网穿透部署Grafana,不能通过localhost读取Prometheus,所以先需要把Prometheus进行内网穿透。当然,Grafana也可以同时穿透一下。
frpc.ini加上这两个,端口自己挑没用的就行。
1
2
3
4
5
6
7
8
9
10
11
|
[ilab_prometheus]
type = tcp
local_ip = 127.0.0.1
local_port = 9090
remote_port = 29090
[ilab_grafana]
type = tcp
local_ip = 127.0.0.1
local_port = 3000
remote_port = 23000
|
具体的frps和frpc的搭建之前写过了,这里不再赘述。
不了解的可以查看:https://blog.engine.wang/posts/frp-notes
先Docker启动一个:
1
2
3
4
5
|
docker run -d \
--name=grafana \
-p 3000:3000 \
--restart always \
grafana/grafana
|
访问穿透ip:23000,进入Grafana
先去Connections,选择Connect data里的Prometheus,这里不要用localhost了,用Prometheus穿透的外网,否则访问不到:

前往仪表盘,Import Dashboard
添加ID: 1860,节点基本信息监控,https://grafana.com/grafana/dashboards/1860-node-exporter-full/
添加ID: 14574,GPU监控,https://grafana.com/grafana/dashboards/14574-nvidia-gpu-metrics/
添加ID: 14282,Docker监控,https://grafana.com/grafana/dashboards/14282-cadvisor-exporter/
后续也可以配置域名和HTTPS,之前有写过,这里就不赘述了