k8s搭建的一些难点:
- 需要多台服务器,贵
- 搭建时需要科学上网
- 搭建比较复杂,学习起来也比较复杂
如果是学习阶段,也接触不到大型集群,可以在本地局域网进行搭建。
因为在学习k8s,但是要搭建集群的话最少也要两台机子(虚拟机也可以但是不太喜欢虚拟机),然而去云服务商租的话又太贵了,因为至少需要两核,所以就使用了本地局域网下的两台主机进行k8s搭建。其中一台主力机作为master,一台之前闲鱼收的废品mac mini 2012作为slave,之前内存只有4G(2+2),拆机升级到了10G(2+8),好在这个cpu有两个核心。
|
角色 |
OS |
MEM |
CPU |
核心数 |
| 台式工作站 |
Master |
Ubuntu 18.04 |
32G |
i7-10700 |
8 |
| Mac mini 2012 |
Slave |
Ubuntu 18.04 |
10G |
i5-3210M |
2 |
后面的操作都是以普通用户来操作,不直接用root因为不安全。
首先关闭swap
1
2
3
4
|
# 关闭swap
$ swapoff -a
# 检查swap是否被成功关掉了
$ free -m
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
# (Install Docker CE)
## Set up the repository:
### Install packages to allow apt to use a repository over HTTPS
$ sudo apt-get update && apt-get install -y \
apt-transport-https ca-certificates curl software-properties-common gnupg2
# Add Docker’s official GPG key:
$ sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg | \
sudo apt-key add -
# Add the Docker apt repository:
$ sudo add-apt-repository \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable"
# Install Docker CE
$ sudo apt-get update && sudo apt-get install -y \
containerd.io=1.2.13-1 \
docker-ce=5:19.03.8~3-0~ubuntu-$(lsb_release -cs) \
docker-ce-cli=5:19.03.8~3-0~ubuntu-$(lsb_release -cs)
$ sudo vim /etc/docker/daemon.json
# 写入以下内容到该文件中
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2"
}
sudo mkdir -p /etc/systemd/system/docker.service.d
# Restart Docker
$ systemctl daemon-reload
$ systemctl restart docker
$ sudo usermod -aG docker ${USER} #当前用户加入docker组
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# Update the apt package index and install packages needed to use the Kubernetes apt repository:
$ sudo apt-get update
$ sudo apt-get install -y apt-transport-https ca-certificates curl
# Install kubeadm
$ sudo curl -s https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | sudo apt-key add -
# Add the Kubernetes apt repository
$ sudo tee /etc/apt/sources.list.d/kubernetes.list <<-'EOF'
deb https://mirrors.aliyun.com/kubernetes/apt kubernetes-xenial main
EOF
# Update apt package index, install kubelet, kubeadm and kubectl
$ sudo apt-get update
$ sudo apt-get install -y kubelet kubeadm kubectl
$ sudo apt-mark hold kubelet kubeadm kubectl
|
这是最关键的一步
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
$ sudo kubeadm init --apiserver-advertise-address=192.168.50.175 --pod-network-cidr=10.244.0.0/16 --image-repository registry.aliyuncs.com/google_containers
[init] Using Kubernetes version: v1.25.0
[preflight] Running pre-flight checks
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
...
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.50.175:6443 --token 89yinf.x0qkzypt93f7o456 \
--discovery-token-ca-cert-hash sha256:dea38ffb2e70723ecf808bec225e222affa13c5061a83b3ac9b215a8be946af5
|
如果要重新init,需要先停止服务,否则就会报错端口被占用,还要删除$HOME/.kube文件夹
1
2
3
4
|
# 需要sudo
sudo kubeadm reset
sudo rm -rf $HOME/.kube
sudo rm -rf /var/lib/etcd
|
复制kubeconfig
1
2
3
|
$ mkdir -p $HOME/.kube
$ sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
$ sudo chown $(id -u):$(id -g) $HOME/.kube/config
|
以Flannel为例:
首先解除master的污点,使其也可以调度pod
1
2
|
kubectl taint nodes --all node-role.kubernetes.io/control-plane-
kubectl taint nodes --all node-role.kubernetes.io/master-
|
一开始创建的时候声明为10.244.0.0/16,这里就不需要改
1
2
3
4
|
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
# 安装flannel
kubectl create -f kube-flannel.yml
|
1
2
3
|
$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
master Ready control-plane 3m58s v1.25.0 192.168.50.174 <none> Ubuntu 20.04.5 LTS 5.15.0-46-generic containerd://1.6.8
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
$ sudo kubeadm join 192.168.50.175:6443 --token 89yinf.x0qkzypt93f7o456 \
--discovery-token-ca-cert-hash sha256:dea38ffb2e70723ecf808bec225e222affa13c5061a83b3ac9b215a8be946af5
[preflight] Running pre-flight checks
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
|
主节点
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# 查看已加入的节点
$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
engine-macmini Ready control-plane 21m v1.25.0 192.168.50.175 <none> Ubuntu 18.04.6 LTS 5.4.0-132-generic containerd://1.6.9
master Ready <none> 52s v1.25.0 192.168.50.174 <none> Ubuntu 20.04.5 LTS 5.15.0-56-generic containerd://1.6.10
# 查看集群状态
$ kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health":"true","reason":""}
|
1
2
3
4
5
6
7
8
9
10
11
12
|
$ kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-flannel kube-flannel-ds-kx57t 1/1 Running 0 11m
kube-flannel kube-flannel-ds-ps82g 1/1 Running 0 26m
kube-system coredns-565d847f94-v5574 1/1 Running 0 31m
kube-system coredns-565d847f94-vg6p5 1/1 Running 0 31m
kube-system etcd-engine-macmini 1/1 Running 1 31m
kube-system kube-apiserver-engine-macmini 1/1 Running 1 31m
kube-system kube-controller-manager-engine-macmini 1/1 Running 1 31m
kube-system kube-proxy-49bq9 1/1 Running 0 11m
kube-system kube-proxy-hc858 1/1 Running 0 31m
kube-system kube-scheduler-engine-macmini 1/1 Running 1 31m
|
https://kubernetes.io/zh-cn/docs/tasks/access-application-cluster/web-ui-dashboard/
1
|
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.5.0/aio/deploy/recommended.yaml
|
https://github.com/kubernetes/dashboard/blob/master/docs/user/access-control/creating-sample-user.md
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
$ vim dashboard-adminuser.yaml
# 写入以下内容
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kubernetes-dashboard
|
1
|
kubectl apply -f dashboard-adminuser.yaml
|
1
2
|
kubectl -n kubernetes-dashboard create token admin-user
# 会输出一长串token,复制登录即可
|

如果要删除用户:
1
2
|
kubectl -n kubernetes-dashboard delete serviceaccount admin-user
kubectl -n kubernetes-dashboard delete clusterrolebinding admin-user
|
1
2
3
|
# 开启proxy,设置address使得非本机也可以访问
$ nohup kubectl proxy --address='0.0.0.0' --port=8001 --accept-hosts='.*' &
$ nohup kubectl port-forward -n kubernetes-dashboard --address 0.0.0.0 service/kubernetes-dashboard 8080:443 &
|
只能http
http://localhost:8001/api/v1/namespaces/kubernetes-dashboard/services/https:kubernetes-dashboard:/proxy/
只能https
修改service kubernetes-dashboard,最后的ClusterIP改为NodePort。查看Service:
1
2
3
4
5
6
7
|
$ get svc --all-namespaces
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 13h
k8s-learning nginx ClusterIP None <none> 80/TCP 7h28m
kube-system kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 13h
kubernetes-dashboard dashboard-metrics-scraper ClusterIP 10.103.123.173 <none> 8000/TCP 13h
kubernetes-dashboard kubernetes-dashboard NodePort 10.105.70.41 <none> 443:30659/TCP 13
|
这里映射到了30659,访问:
https://<master_ip>:30659即可
如果是Chrome可能在点击详情看不到不安全仍然访问的按钮,而是直接报错连接不私密。此时任意点击网页中的空白的地方,然后输入thisisunsafe,回车就可以访问了。
如果是在有公网IP的云服务器搭建,则无法通过http登录,但是不在一个局域网直接https也不行,有两种方式:
- 简单
转发到8001之后,本地转发云端的8081到本地的8081
1
|
ssh -L localhost:8001:localhost:8001 -NT ubuntu@ip
|
然后本机访问
http://localhost:8001/api/v1/namespaces/kubernetes-dashboard/services/https:kubernetes-dashboard:/proxy/
即可
- 配置HTTPS证书
这个复杂一些,之后如果实际经历了再写
登录的话将之前的token复制进去即可登录
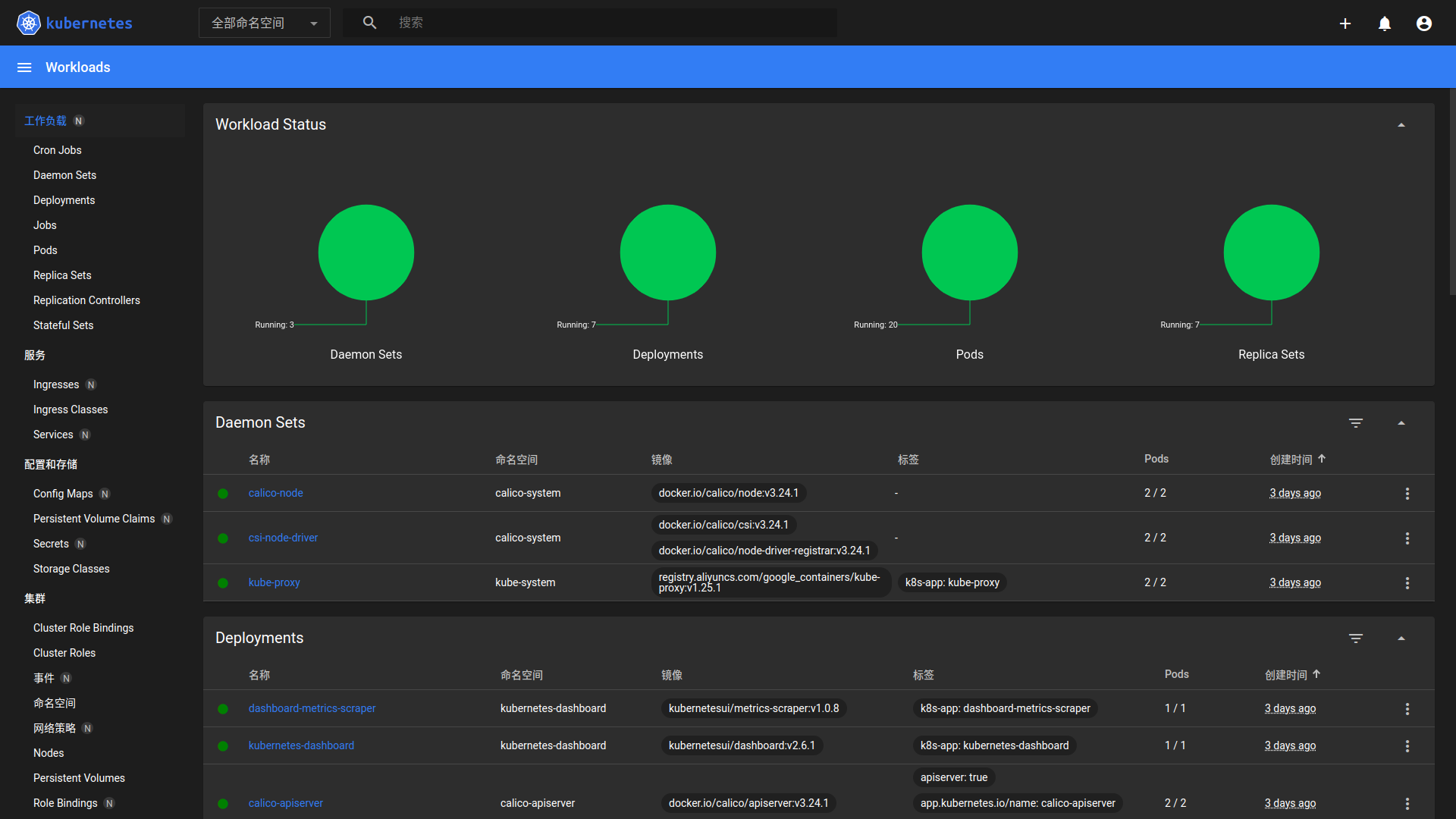
dashboard的token默认15分钟就会过期,不太方便,可以修改从而延长过期时间。
取Deployment找到kubernetes-dashboard,进行修改:
1
2
3
4
5
6
7
8
|
spec:
...
containers:
- name: kubernetes-dashboard
image: kubernetesui/dashboard:v2.6.1
args:
...
- '--token-ttl=43200'
|
这样就将token延长到了43200秒,也就是12小时
The connection to the server 192.168.50.175:6443 was refused - did you specify the right host or port?
master节点重启,可能会报这个错。
1
2
|
$ sudo swapoff -a
$ strace -eopenat kubectl version
|
[ERROR CRI]: container runtime is not running: output: E0812
1
2
|
$ sudo rm -rf /etc/containerd/config.toml
$ systemctl restart containerd
|
coredns一直pending,无法调度
1
2
|
kube-system coredns-565d847f94-99kh9 0/1 Pending 0 4m55s
kube-system coredns-565d847f94-rhmr4 0/1 Pending 0 4m55s
|
检查对应的pod:
1
2
3
|
$ kubectl describe pods -n kube-system coredns-565d847f94-99kh9
...
Warning FailedScheduling 3m9s (x2 over 8m26s) default-scheduler 0/1 nodes are available: 1 node(s) had untolerated taint {node.kubernetes.io/disk-pressure: }. preemption: 0/1 nodes are available: 1 Preemption is not helpful for scheduling.
|
看到这里是遇到了node.kubernetes.io/disk-pressure,主机磁盘空间不足,进行空间清理
coredns一直Container Creating,查看发现报错是 plugin type="calico" failed (add): error getting ClusterInformation: Get "https://10.96.0.1:443/apis/crd.projectcalico.org/v1/clusterinformations/default": dial tcp 10.96.0.1:443: i/o timeout
calico没卸干净,先卸载br开头的、calico的、Tunl0的网卡
网卡相关的错误,很多可以通过卸载网卡来解决,卸载掉比如br开头的,以及calico、flannel相关的网卡(如果要卸载的话)
1
2
3
4
5
6
|
su
ip a
ifconfig <网卡id> down
ip link delete <网卡id>
rm -rf /var/lib/cni/
rm -f /etc/cni/net.d/*
|
然后去/etc/cni/net.d/把所有calico相关的都删掉
参考 https://qiaolb.github.io/remove-calico.html
dashboard失败,报错failed to set bridge addr: "cni0" already has an IP address different from 10.244.1.1/24
此时是master或者node已经有cni0网卡,但是和flannel冲突,一般是node的问题,去node删除cni0网卡。此时dashboard正常,但是这样又造成了coredns的网卡被挤掉了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
$ kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-flannel kube-flannel-ds-kx57t 1/1 Running 0 22m
kube-flannel kube-flannel-ds-ps82g 1/1 Running 0 36m
kube-system coredns-565d847f94-v5574 0/1 Running 2 (84s ago) 42m
kube-system coredns-565d847f94-vg6p5 0/1 Running 2 (74s ago) 42m
kube-system etcd-engine-macmini 1/1 Running 1 42m
kube-system kube-apiserver-engine-macmini 1/1 Running 1 42m
kube-system kube-controller-manager-engine-macmini 1/1 Running 1 42m
kube-system kube-proxy-49bq9 1/1 Running 0 22m
kube-system kube-proxy-hc858 1/1 Running 0 42m
kube-system kube-scheduler-engine-macmini 1/1 Running 1 42m
kubernetes-dashboard dashboard-metrics-scraper-748b4f5b9d-vm4xj 1/1 Running 0 9m16s
kubernetes-dashboard kubernetes-dashboard-5dff5767b9-rtkc6 1/1 Running 0 9m16s
|
此时delete掉两个coredns即可恢复。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
$ kubectl delete pod -n kube-system coredns-565d847f94-v5574
pod "coredns-565d847f94-v5574" deleted
$ dashboard kubectl delete pod -n kube-system coredns-565d847f94-vg6p5
pod "coredns-565d847f94-vg6p5" deleted
$ dashboard kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-flannel kube-flannel-ds-kx57t 1/1 Running 0 22m
kube-flannel kube-flannel-ds-ps82g 1/1 Running 0 37m
kube-system coredns-565d847f94-fdflx 1/1 Running 0 9s
kube-system coredns-565d847f94-vhddz 1/1 Running 0 21s
kube-system etcd-engine-macmini 1/1 Running 1 42m
kube-system kube-apiserver-engine-macmini 1/1 Running 1 42m
kube-system kube-controller-manager-engine-macmini 1/1 Running 1 42m
kube-system kube-proxy-49bq9 1/1 Running 0 22m
kube-system kube-proxy-hc858 1/1 Running 0 42m
kube-system kube-scheduler-engine-macmini 1/1 Running 1 42m
kubernetes-dashboard dashboard-metrics-scraper-748b4f5b9d-vm4xj 1/1 Running 0 9m53s
kubernetes-dashboard kubernetes-dashboard-5dff5767b9-rtkc6 1/1 Running 0 9m53s
|