容器本质上是一种沙盒技术,像一个集装箱,将应用装起来。
这样应用与应用不会互相干扰,装进集装箱的应用也可以非常方便的迁移,在不同的地方也能保持一样的环境。
如何实现这个边界?
一个简单的程序编译后式一段二进制文件和一些外部的输入文件,运行的时候变成了寄存器的值、内存中的数据、堆栈中的指令、被打开的文件等等,总和就是进程。
容器的核心功能,就是通过约束和修改进程的动态表现,为其创造出一个边界。
Linux的Cgroups技术是用来制造约束的主要方法,Namespace技术是用来修改进程视图的主要方法。
Linux Namespace是Linux提供的一种内核级别环境隔离的方法,它可以使得容器内的进程运行的时候看不到宿主机的进程,比如PID是重新计算的,每个容器的PID=1的超级父进程都是自己,看不到其他的Namespace。Namespace可以创建一个全新的进程空间,当然除了PID还有UTS、IPC、mount、PID、network、User等Namespace,可以对进程的各种上下文都进行遮挡蒙蔽。
包含三个系统调用:
clone():创建一个新的进程,通过传入参数进行隔离。这个比较重要,后面单独拿一节来讲。
unshare():将某个进程脱离某个namespace
setns():将某个进程加入某个namespace
所以Docker实际上就是在创建容器进程时,指定了进程启动的一组Namespace参数,这样容器进程就只能看到当前Namespace限定的资源、文件、状态等,宿主机和其他Namespace的进程都看不到了。
所以其实各个应用并不是运行在Docker Engine的东西上:

而是通过Docker配置的Namespace进行了分离:
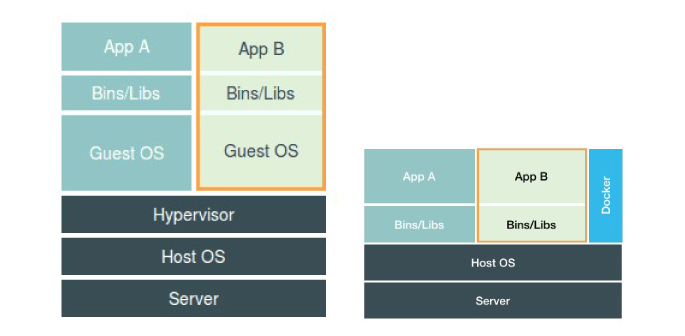
上图左边是虚拟机,是对硬件的虚拟化,右图是Docker,通过Namespace对应用进程进行隔离。
clone系统很重要,称之为容器的基石也不为过。
1
|
int clone(int (*fn)(void *), void *child_stack, int flags, void *arg, ...)
|
flags包括:
CLONE_NEWIPC
CLONE_NEWNET
CLONE_NEWNS
CLONE_NEWPID
CLONE_NEWUTS
CLONE_NEWUSER
比如
1
|
pid_t child_pid = clone(child_func, child_stack, CLONE_NEWPID | CLONE_NEWNS | SIGCHLD, NULL);
|
这些选项可以指定新的进程可以看到的东西。
如果没有加参数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
static int child_func() {
printf("PID: %ld\n", (long)getpid());
printf("PPID: %ld\n", (long)getppid());
system("whoami");
return 0;
}
int main() {
pid_t child_pid = clone(child_func, child_stack + STACK_4M, SIGCHLD, NULL);
printf("clone() = %ld\n", (long)child_pid);
waitpid(child_pid, NULL, 0);
return 0;
}
|
没有指定参数,这个子进程就可以看到真实的世界,比如pid,输出就是:
1
2
3
4
|
clone() = 316667
PID: 316667
PPID: 316666
engine
|
clone返回的子进程的pid,和子进程看到的自己的pid是一样的。user id也和原来一样。
如果增加一些参数,相当于用各种遮罩将子进程遮住,它就看不见对应模块的真实世界了。
改成
1
|
pid_t child_pid = clone(child_func, child_stack + STACK_4M, SIGCHLD, NULL);
|
现在再运行:
1
2
3
4
|
clone() = 317773
PID: 1
PPID: 0
nobody
|
子进程就不知道外面的世界了。父进程是知道子进程的pid的,但是子进程不知道外面的一切。
子进程增加:
1
2
3
|
pid_t pid = fork();
char * const args[] = { "/bin/bash", NULL};
execv(args[0], args);
|
也就是说会fork一个新的进程并启动一个bash,就会直接进入一个新的bash:
1
2
3
4
5
6
|
[engine@dev code]$ ./pid_test
clone() = 318630
PID: 1
PPID: 0
nobody
[nobody@dev workspace]$
|
进入后会发现大部分环境就像一个全新的世界,和宿主机没关系,但是ps、top等指令还是可以看到外面的世界,因为这些是通过挂载于/proc的文件系统获取的,所以需要加上CLONE_NEWNS,还需要重新挂载proc。
这样就没问题了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
pid_t child_pid = clone(child_func, child_stack + STACK_4M,
CLONE_NEWNS | CLONE_NEWPID | CLONE_NEWUSER | SIGCHLD, NULL);
static int child_fn() {
printf("PID: %ld\n", (long)getpid());
printf("PPID: %ld\n", (long)getppid());
char *mount_point = "/proc";
mkdir(mount_point, 0555);
if(mount("proc", mount_point, "proc", 0, NULL) == -1) {
printf("error when mount\n");
}
pid_t pid = fork();
if(pid == 0) {
char * const args[] = { "/bin/bash", NULL};
execv(args[0], args);
} else {
wait(NULL);
}
return 0;
}
|
然而由于多个容器之间使用的还是宿主系统的操作系统内核,隔离的并不彻底。
如果只采用Namespace,还是无法运行跨平台的容器。
会有以下的问题:
- Linux内核中有很多资源和对象不能被Namespace化,比如时间。如果某个容器进程修改了时间,那么会影响宿主。
- 同时也会带来安全问题,很容易从容器中攻击到宿主机。
- 隔离的不够彻底,比如各个容器之间还会争夺宿主机资源。
...
Linux Cgroups(Linux Control Group)就是Linux内核中用来为进程设置资源限制的一个功能,可以设置进程的资源上限,包括CPU、带宽、内存、磁盘等。
Cgroups以文件和目录的方式组织在/sys/fs/cgroup下。可以用mount -t cgroup展示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
# CentOS 8.2
$ mount -t cgroup
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
cgroup on /sys/fs/cgroup/rdma type cgroup (rw,nosuid,nodev,noexec,relatime,rdma)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpu,cpuacct)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_cls,net_prio)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
|
/sys/fs/cgroup下面挂载了很多诸如cpu、pids、memory、systemd这样的子目录。表示这些资源都可以被Cgroup所限制。
每个资源子目录下是各种控制组,比如cpu的:
1
2
3
4
5
6
|
$ ls /sys/fs/cgroup/cpu
cgroup.clone_children cpuacct.usage_all cpuacct.usage_user cpu.shares release_agent
cgroup.procs cpuacct.usage_percpu cpu.cfs_period_us cpu.stat system.slice
cgroup.sane_behavior cpuacct.usage_percpu_sys cpu.cfs_quota_us init.scope tasks
cpuacct.stat cpuacct.usage_percpu_user cpu.rt_period_us notify_on_release user.slice
cpuacct.usage cpuacct.usage_sys cpu.rt_runtime_us onion YunJing
|
这里各个文件是全局配置,但是里面的文件夹是控制组,比如这里腾讯云的YunJing文件夹,里面是控制组内的各种配置
各个文件是各种配置,比如cpu.cfs_quota_us限制cpu资源,默认是-1不限制,如果写入10000,就表示每100ms cpu的时间中,该控制组限制的进程只能使用10ms,最高只能使用10%的cpu。
如何将进程加入控制组,只需要将pid写入tasks即可。
所以可以把Cgroups理解为一个子系统目录+一组资源限制文件
Docker只需要为每个容器创建一个控制组,启动之后将进程的pid填入对应控制组的tasks中即可。
Docker运行容器时的参数也就是会指定这些控制组的资源文件的内容,比如:
1
|
$ docker run -it --cpu-period=100000 ubuntu /bin/bash
|
运行之后,去对应容器控制组的cpu资源限制文件里查:
1
2
|
$ cat /sys/fs/cgroup/cpu/docker/5d5c9f67d/cpu.cfs_period_us
100000
|
Cgroups的一个问题就是/proc文件系统是不清楚Cgroups的,也就是说在容器中运行top显示的还是宿主机的资源使用情况。
容器的本质是一种特殊的进程。一个正在运行的 Docker 容器,其实就是一个启用了多个 Linux Namespace 的应用进程,而这个进程能够使用的资源量,则受 Cgroups 配置的限制。
每个Docker容器都是单进程的,一个容器中不能运行两个应用。
容器相当于被Namespace蒙蔽了双眼,只能看到自己的一小片天地,误以为世界就这么大。又被Cgroups限制了资源,只能拥有一部分规定的资源。它发挥着唯一的意义,就是和里面运行的应用程序同生共死。多么悲壮的一生!